Robotic Foundation Models - Comparing $\pi_0$ and RT-2
As a software engineer, one of my biggest conundrums was how machines can beat humans on Go and predict protein structures, but yet they cannot fold laundry, which is such a basic task for humans? Apparently this question has a name, Moravec’s paradox, which describes how easy it is for AI to master extremely complex reasoning while it is surprisingly difficult to perform basic tasks involving simple movements.
However, we might not be that far away from the “ChatGPT moment” for robotics. The concept of robotics foundation models seem to shed light towards building a generalist robotic software where it can perform multiple tasks smoothly. I recently learned about the two important breakthroughs, RT-2 and $\pi_0$, from Google DeepMind and Physical Intelligence, respectively. Here are my notes studying them, focusing on what enabled them to learn how to “fold laundry”.
RT-2: A vision-language-action model (VLA) acting with language.
RT-2 represents a breakthrough in directly transferring the knowledge contained within web-scale vision-language models (VLMs) into robotic control, without having a separate robotic “head” to a VLM. Since it directly outputs the action sequence predictions, the authors categorize RT-2 as a vision-language-action (VLA) model.
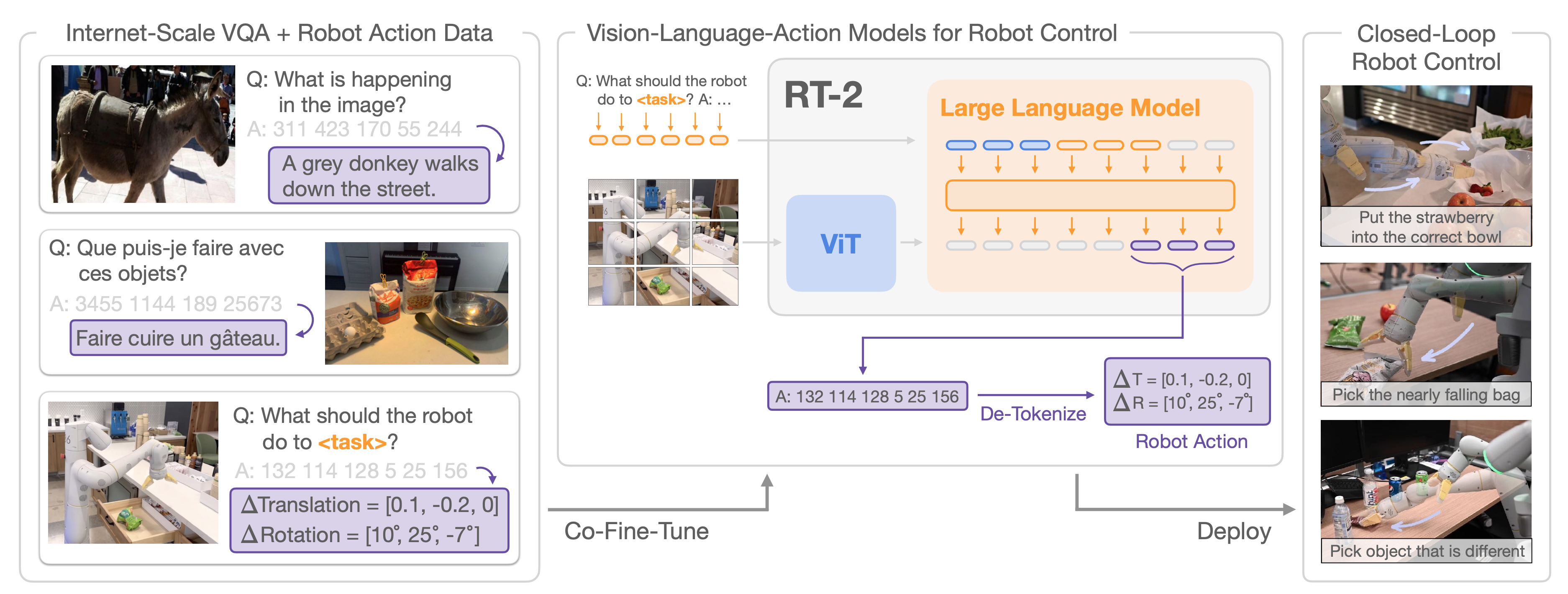
RT-2 overview. Source: RT-2 Paper
- Core Idea: The key idea is to re-frame robot control as a sequence modeling problem, integrating actions into the VLM’s vocabulary. Specifially, several tokens are reserved for representing actions, encoding the action space consisting of 6 degree-of-freedom positional and rotational displacement, robot gripper extension level, and termination signal. In this manner, action sequences can be considered as another “language” that the VLM should provide answers in.
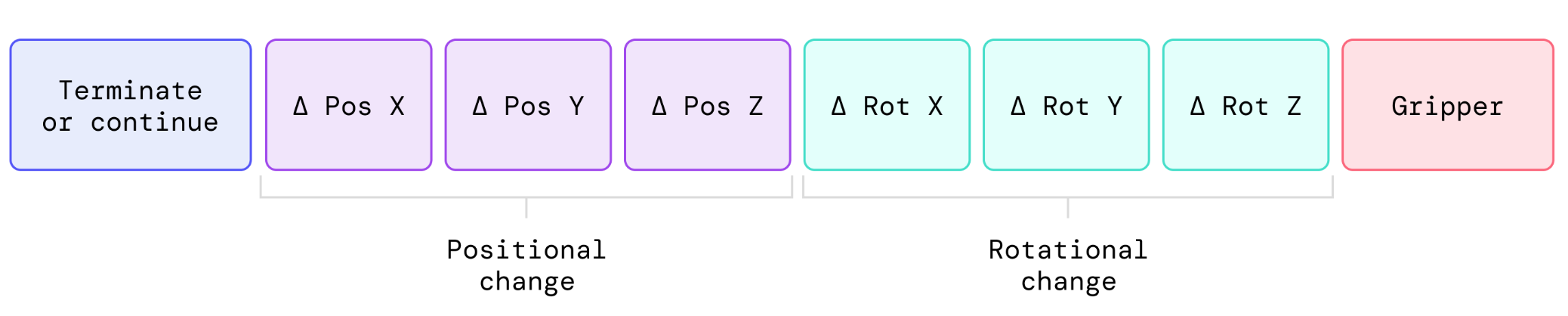
RT-2 action space encoded as action tokens. Source: RT-2 Project Page
-
Architecture: RT-2 is built upon a pre-trained VLM such as PaLI-X and PaLM-E. It takes a visual input and natural-language instructions and outputs sequences of natural language or robotic action tokens.
-
Crucial Step: Co-fine-tuning: The pre-trained VLM is fine-tuned to answer action sequences to become a VLA model. RT-2 employs co-fine-tuning, meaning the entire VLM’s parameters are further trained simultaneously on a mixture of its original web-scale-vision-language data and new robotic trajectory data. The robotic data consists of examples pairing observations (robot camera image and textual task description including a verb like “pick up” and an object “the apple”) with the corresponding action token sequences that achieved the task. The author claims that co-fine-tuning is the key to a more generalized policy model by exposing it to a vast amount of web-scale abstract visual data.
-
Generalization: Co-fine-tuning unlocks semantic generalization, by achieving tasks that were unseen during fine-tuning. It performed ~2x better on unseen tasks (unseen objects, unseen backgrounds, and unseen environments) compared to the baselines RT-1 and MOO.
-
Limitations: The author points out that although RT-2 was able to generalize over visual concepts through internet-scale pre-training data for VLM, it cannot perform out-of-distribution actions that were never seen during fine-tuning. Also, the computational cost of the model is high, preventing it from performing fast actions.
$\pi_0$: Enhanced Generalization via Cross-Embodiment Training Data and Flow-Matching Action Expert
$\pi_0$ is a VLA that extends RT-2 to build a more generalist robot policy. It can adapt to different robotic platforms with different number of DoFs (e.g. one-arm, two-arm) and perform a variety of tasks, including laundry folding and box assembling.
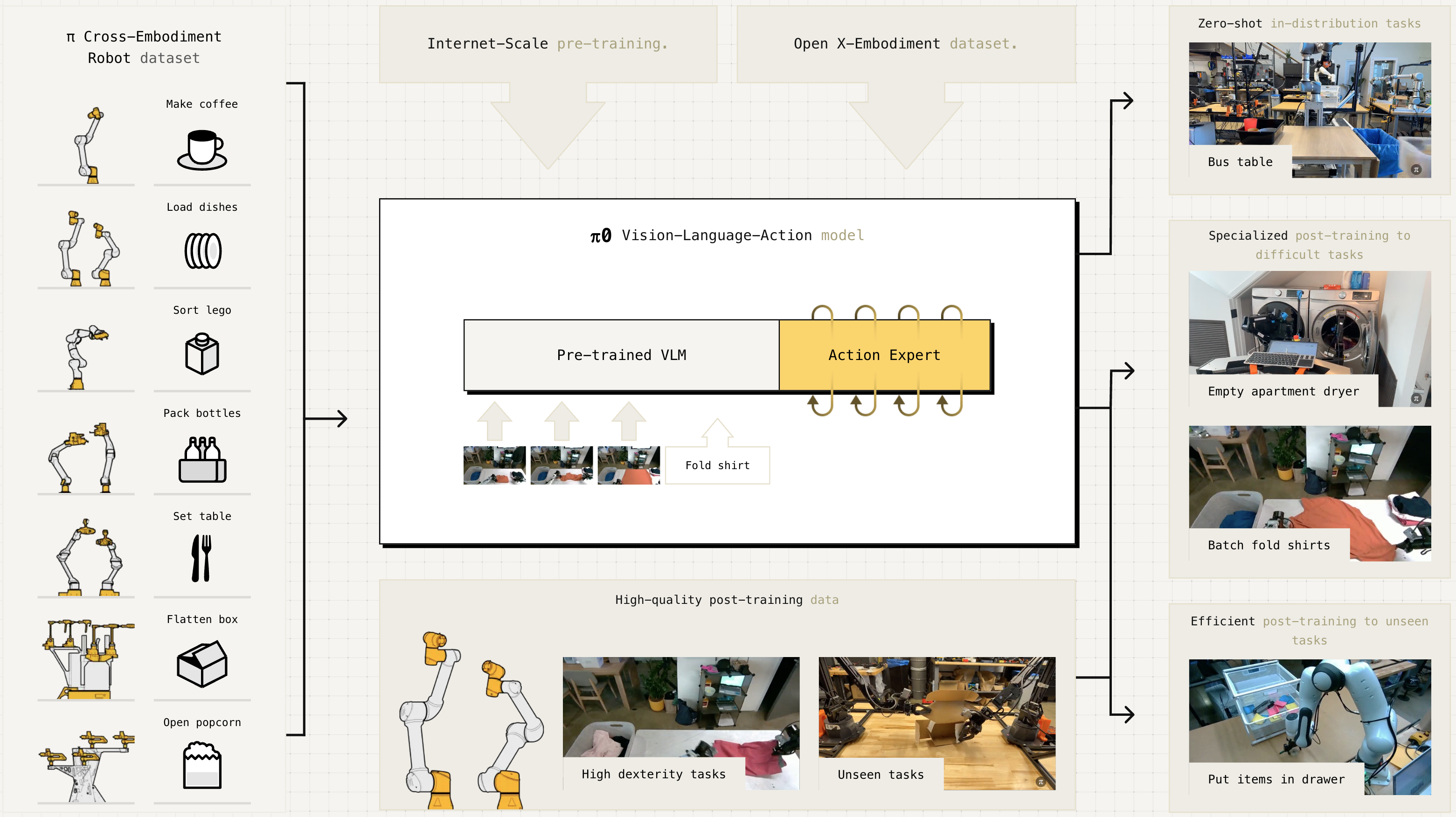
Pi0 overview. Source: pi0 blog post
-
Core Idea: There are two main ideas that allows enhancing generality of the $\pi_0$ model: cross-embodiment training data mixture and flow-matching action expert. Cross-embodiment training data represents robotic task-action (manipulation) datasets collected across 8 different types of robots. Specifically, it consists of a subset of OXE (Open X-embodiment) dataset and the $\pi$ dataset. The action expert is a separate model with distinct weights trained with flow-matching loss , essentially a form of diffusion, that enables smoother fine-grained and complex movements.
-
Architecture: $\pi_0$ consists of a pre-trained Gemma language model, SigLIP image encoder, and an action expert producing about 50 chunks of continuous action predictions. In contrast to RT-2, $\pi_0$’s VLM does not generate action tokens but utilizes the action expert to predict the actions.
-
Generalization: $\pi_0$ can perform a variety of different tasks, such as shirt folding and table bussing, out-of-box via direct prompting and shows better results than the baselines OpenVLA and Octo. The authors also demonstrate effective post-training behavior of $\pi_0$, where it can learn new, unseen tasks after fine-tuning with relatively small amount of 1- or 2-hour high-quality data.
-
Multi-Stage Tasks: With some fine-tuning, $\pi_0$ also demonstrates the capability of executing complex, multi-stage tasks like laundry folding (take out the laundry from the washer, fold it, and stack them on the table) and box building (assemble a box in a flattened state). Baseline models were not able to perform these tasks.
-
Limitations: The optimal dataset mixture that yields more effective training remains unknown. Also, there is an open question of how much diversity in the data results in positive transfer towards generalized robot model.
Conclusion
Both RT-2 and $\pi_0$ represent significant improvements towards overcoming the limitations of previous robot AI models, which were typically confined to a narrow set of actions. By leveraging the power of large language and vision models, these new approaches enable robots to understand and execute tasks with a level of semantic understanding and generalization previously unseen. RT-2 shed light to how a combined vison-language-action (VLA) model can generalize to perform unseen tasks. $\pi_0$ goes further and leverages cross-embodiment data mixture along with flow-matching action export to both generalize on unseen tasks and perform complex, multi-stage tasks such as laundry folding.
There exist further advancements, namely Gemini Robotics and Hi Robot that I plan to review as well. I think we’re entering an age where I no longer have to fold my own laundry!