JDCNet for Singing Voice Melody Detection and Classification
Singing voice melody transcription is one of the difficult tasks in music information retrieval. In order to extract vocal melody lines from a song, one must detect whether there is a voice singing and identify the pitch of the sung melody. Although fairly easy for a human being, this task is difficult to reproduce using computer programs and algorithms. JDCNet is a neural network model that tries to accomplish both tasks at once.
JDCNet
JDCNet, or Joint Detection and Classification Network is a model proposed from a paper: Kum et al. - “Joint Detection and Classification of Singing Voice Melody Using Convolutional Recurrent Neural Networks (2019)”. It is a model that tackles detection of singing voice at each frame along with pitch classification at the same time. The main idea is to aid voice detection objective by utilizing intermediate features from the backbone CRNN (Convolutional Recurrent Neural Network) that performs the classification task.
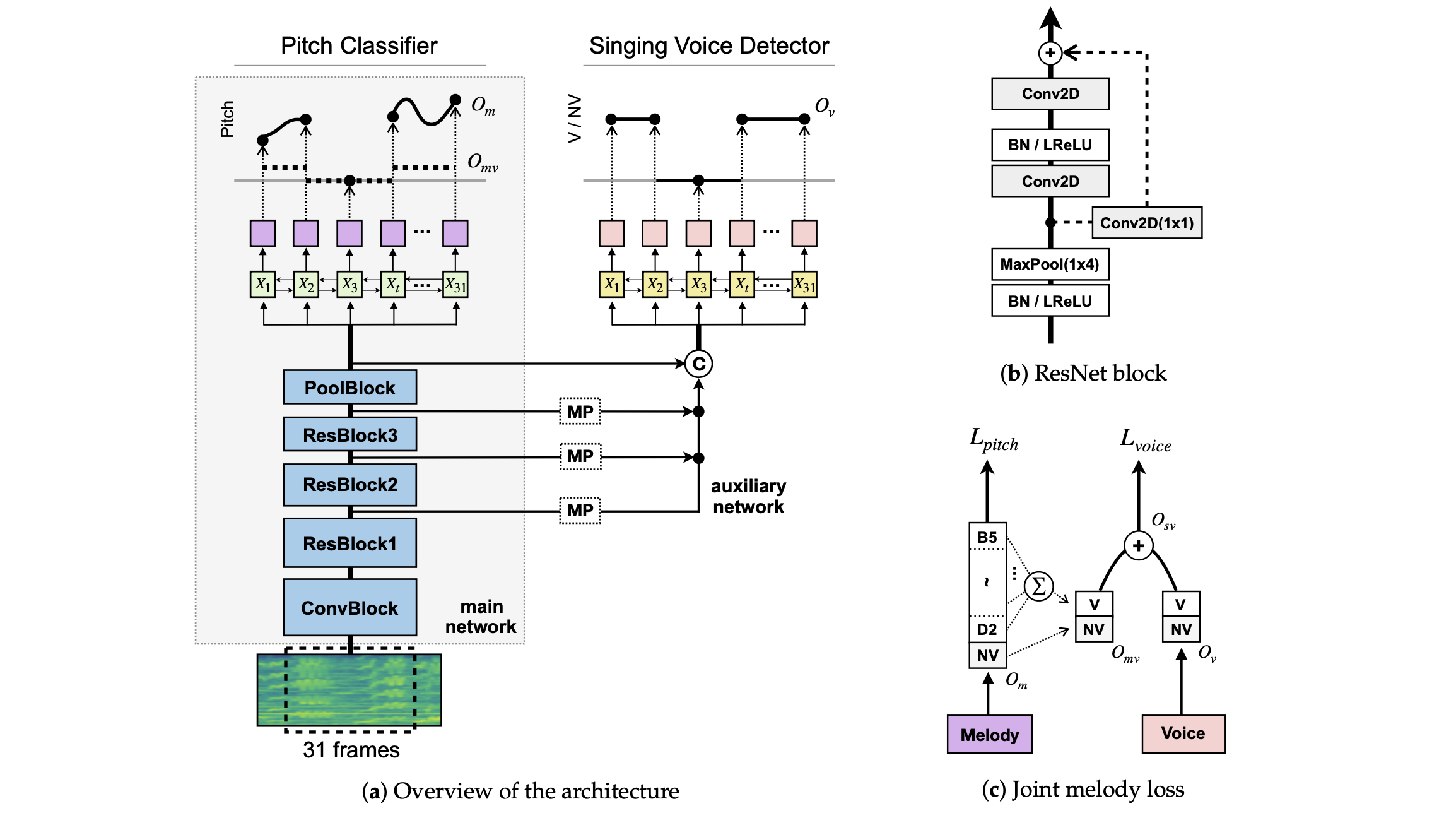
JDCNet Architecture and Joint Melody Loss. Source: original paper
Training JDCNet - in a Nutshell
Inputs and Outputs
The input and output representations of JDCNet are fairly intuitive. Inputs are 31 frames of log-magnitude spectrogram chunks, with 513 frequency bins. There are two different outputs; i) one produced by the pitch classifier, represented as 722-dimensional vectors containing prediction values for each of 722 classes, and ii) another generated by the singing voice detector, represented as 2-dimensional vectors containing voice and non-voice prediction values. 721 classes representing pitch frequency values ranging from notes D3 (MIDI=38) to B5 (MIDI=83) divided into 1/16 semitones and an additional class representing non-voice comprise 722 pitch classes.
Loss
The total loss is a weighted sum of pitch classification loss and voice detection loss.
\[L_{joint} = L_{pitch} + \alpha L_{voice}\]The classification loss is a standard cross-entropy loss, but the label vectors used here are Gaussian-blurred soft labels.
Using these weak labels implies soft penalties for mispredictions when the predicted class is adjacent to the target class.
The detection loss is also a cross-entropy loss applied upon two classes: (voice, non-voice).
Dataset
The model is trained using MedleyDB Dataset - Melody Subset.
Singing Voice Melody Extraction Examples (in MIDI)
Here are some of the extracted melody audio samples. This script takes an audio file as input and extracts melody for the entire audio file as a single MIDI file, using a pre-trained JDCNet model. Generation of these MIDI files does NOT use any smoothing whatsoever - it only goes through a quantization step that rounds the predicted MIDI number to nearest integer.

generated midi file
Male Vocal
Bohemian Rhapsody - Queen
Female Vocal
Someone Like You - Adele
K-Pop Male Vocal
Gangnam Style - Psy
K-Pop Female Vocal
Love Poem - IU
Some Thoughts
Generated MIDI samples all have something in common - the notes seem disassembled, scattered, and frivolous. The main cause of these symptoms might be due to the conditional independence assumption made by this setup. Each frame’s pitch predictions does not depend on the prediction results of adjacent frames. This might account for the octave errors (a common and notorious problem for pitch detection), discontinuations for expected long notes, and mispredictions on adjacent classes. Some causal modeling or even a Generative Adversarial Network (GAN) setup, perhaps imposing a discriminator that forces the generated pitch sequences to be ‘realistic’, might help ameliorate this problem.