CycleGAN Deception
Recently, while trying to reproduce CycleGAN training, I was looking at a rather peculiar phenomenon where each of the CycleGAN generators failed to transform the styles of a real images but perfectly recovered images that have been generated by the other generators. It was a symptom of information hiding, where each generators put secret codes into the generated images so that the other generator is able to use that information to perfectly recover the generated image, thereby greatly reducing the cycle-consistency loss. The information is not visible to in the eye, so for a long time I was wondering why the training failed.
Brief introduction to CycleGAN
 Image from CycleGAN project page
Image from CycleGAN project page
CycleGAN (Cycle-Consistent Generative Adversarial Networks) brought surprise to many of us with the famous ‘horse-to-zebra’ transfigure, back in ICCV 2017, by Zhu, et al. 2017. It is able to successfully and dramatically transform one style of images to another, without explicit pair labeling. We can simply provide two sets of images having different styles, and CycleGAN will be able to transform back and forth.
The novelty of this model was to make use of a pair of GAN models. Each of the generators are responsible for transforming images to another style, and the discriminators would determine whether the transformed image is real or not.
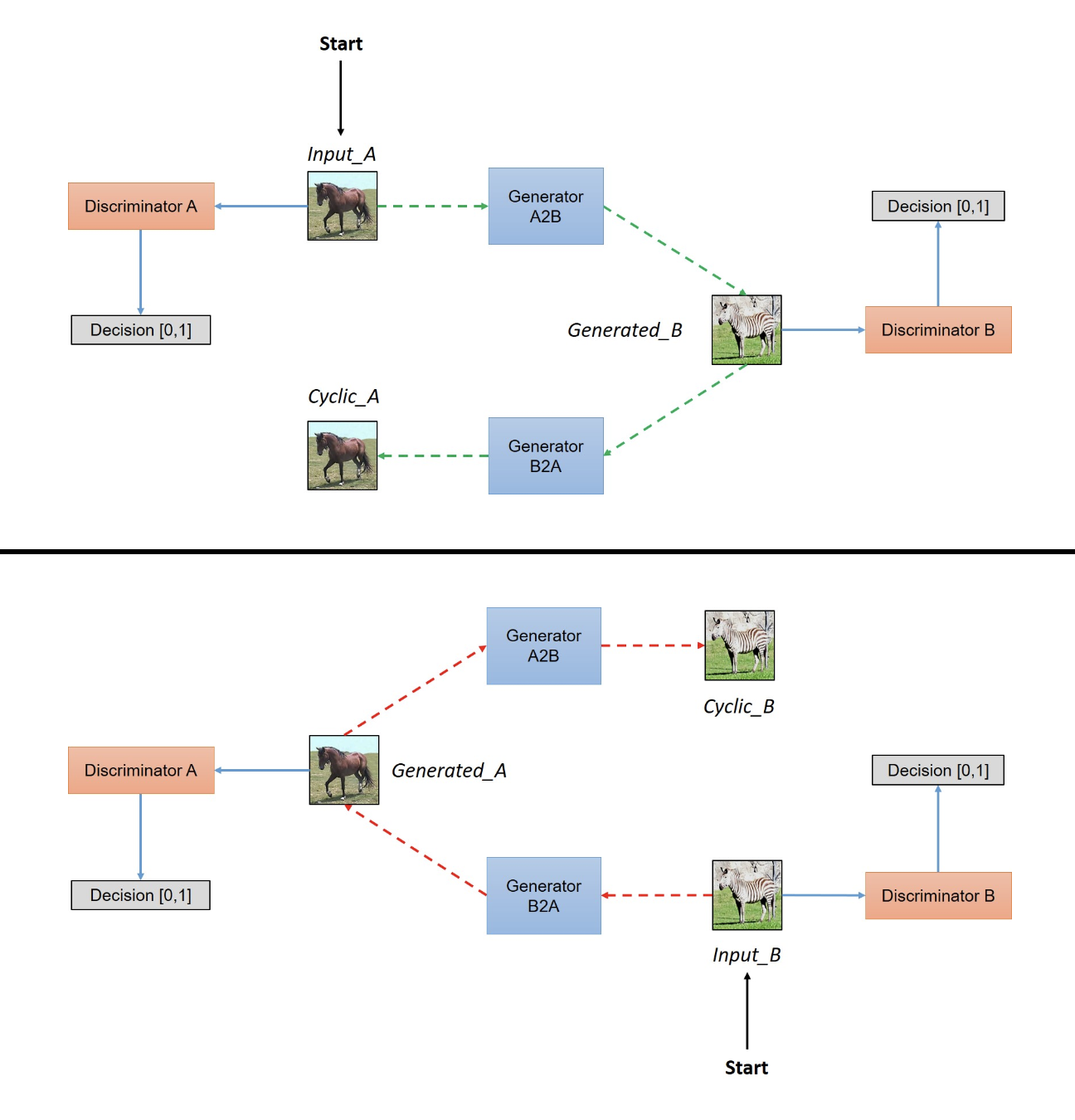 Image from Hardik Bansal’s Post
Image from Hardik Bansal’s Post
Cycle-Consistency Loss
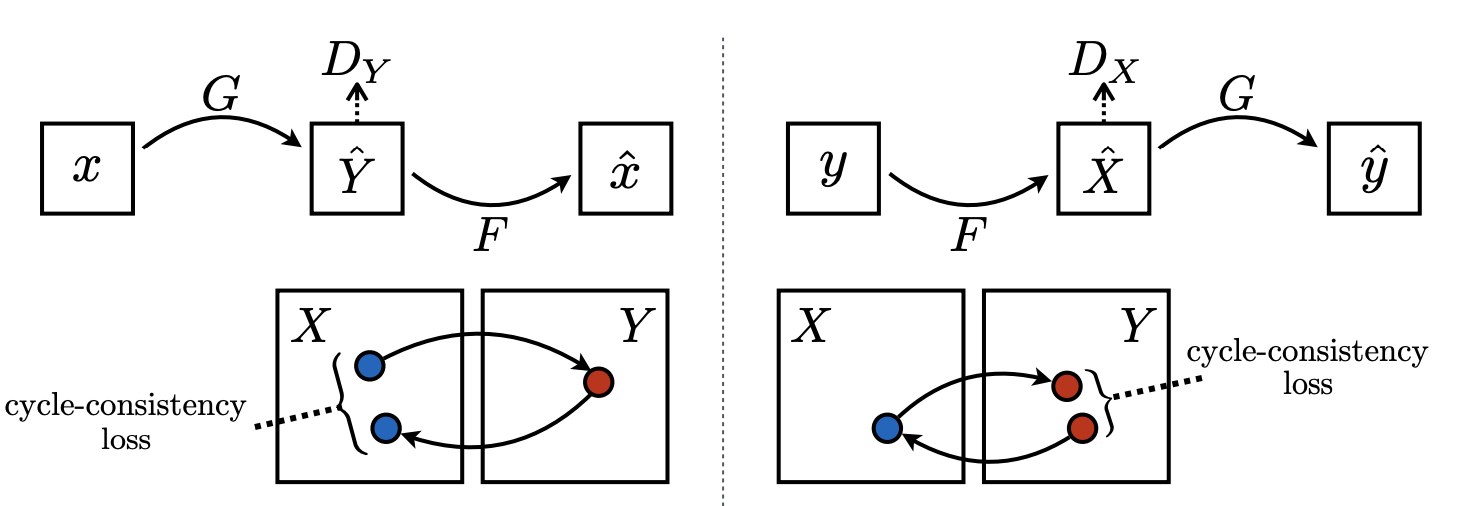 Image from CycleGAN paper
Image from CycleGAN paper
However, rather than training both GAN models independently, the authors devised the cycle-consistency loss in order to maintain transitivity between the two models.
\[\mathcal{Loss}_{cycle-consistency} = \mathbb{E}_{x \sim p_{data}(x)}[\lVert F(G(x)) - x \rVert_{1}] + \mathbb{E}_{y \sim p_{data}(y)}[\lVert G(F(y)) - y \rVert_{1}]\]Enforcing the ‘forward-backward consistency’ seems natural, since in either ways of transformation, the contents of the image should remain intact and only the style should change. This is analogous to language translation, where French translation of “this is my house” is “c’est ma maison”, and it conveys the exact same meaning (content) while only the language (style) have changed. Translating in both ways without damaging the meaning of sentence contents is a requirement, and this is what cycle-consistency loss aims to achieve.
There is also another term to the loss function called the id loss that works to keep the general texture colorscheme of the transformed image relavent, but I won’t go into the details here.
Nice Reconstruction, Bad Generation
While iterating the experiments of transforming monet paintings to photographs, I became frustrated by the low quality of generated images from the photo -> monet generator.
Various tweaks on learning rates, cycle-consistency loss coefficient, and id-loss coefficients did not help at all;
the discriminator for monet paintings seemed to always win over the photo -> monet generator, and this generator would fall into a mode collapse and generate random, noisy images (I didn’t touch the architeture because I wanted to reproduce with the exact same architecture from the paper).
Accordingly, as the generator for photo -> monet failed, the generator for monet -> photo would also result in generating random, colorful images that had nothing to do with original monet painting it was supposed to transform.
This is because the loss value for generators dropped significantly and too small gradients were back-propping through the generator.
However, while this was happening, the reconstructed images and the original images seemed remarkably alike.
The inputs to monet -> photo generator (marked G in the figure) for reconstruction were those random noisy images generated by a failing photo -> monet generator (marked F in the figure),
but, nonetheless, the reconstruction was perfect, giving very low cycle-consistency loss value.
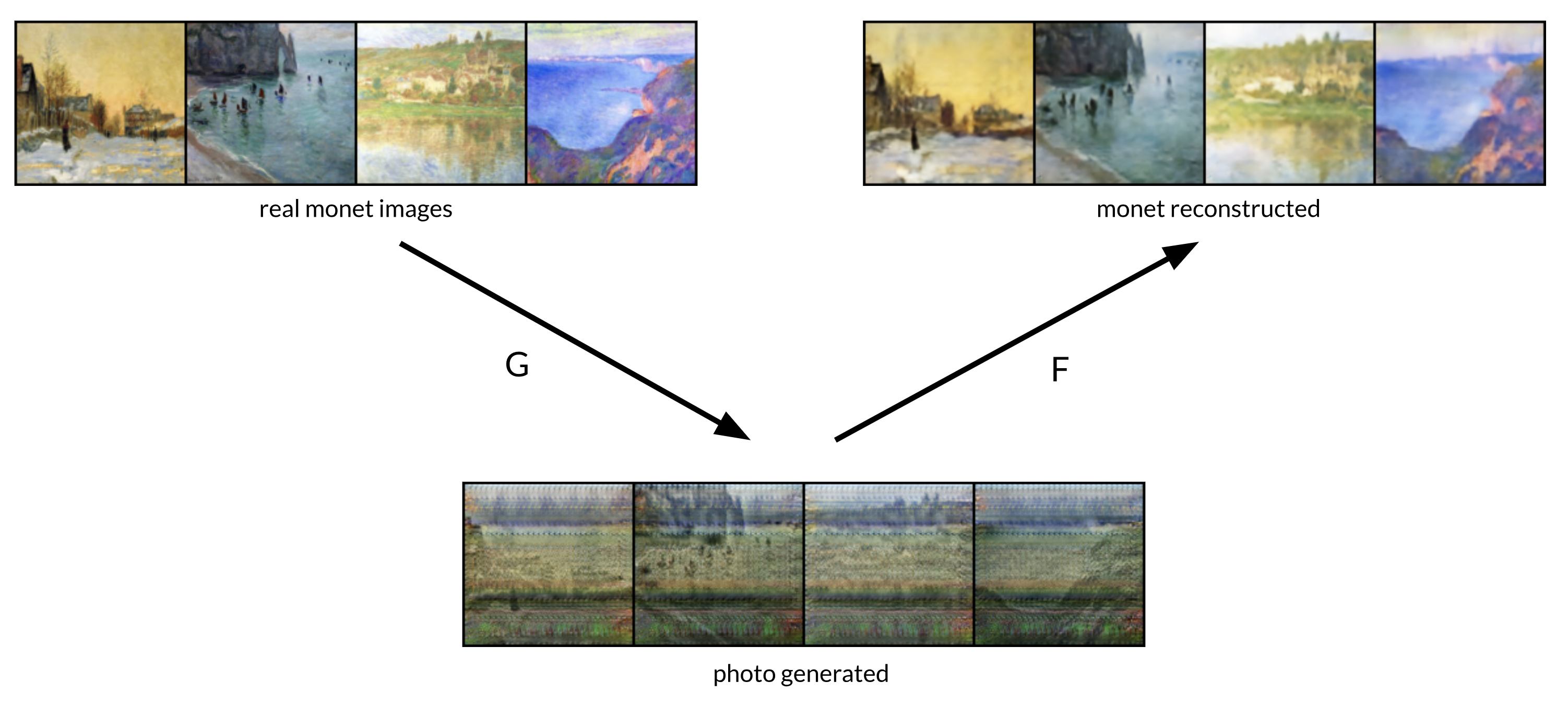
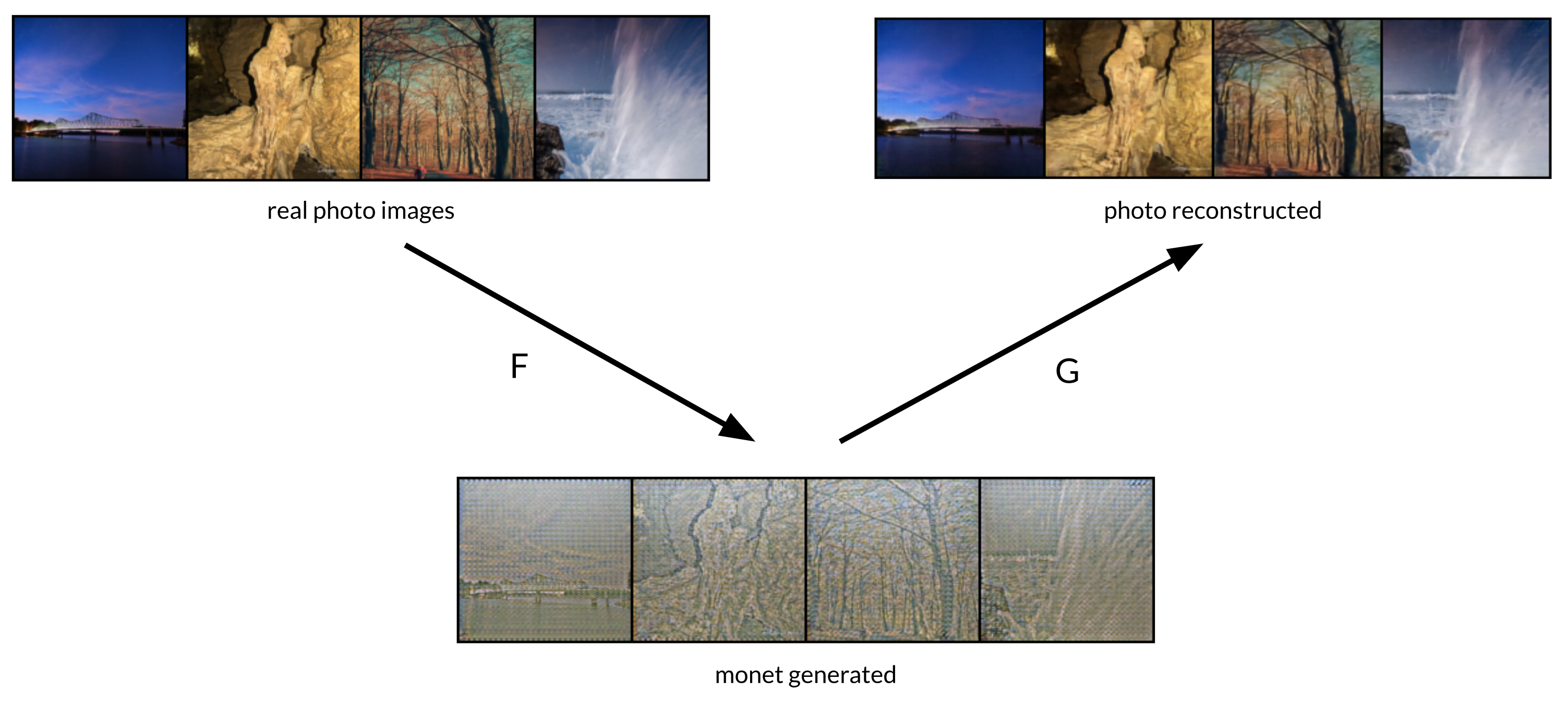 Examples of bad style transfers but perfect reconstructions
Examples of bad style transfers but perfect reconstructions
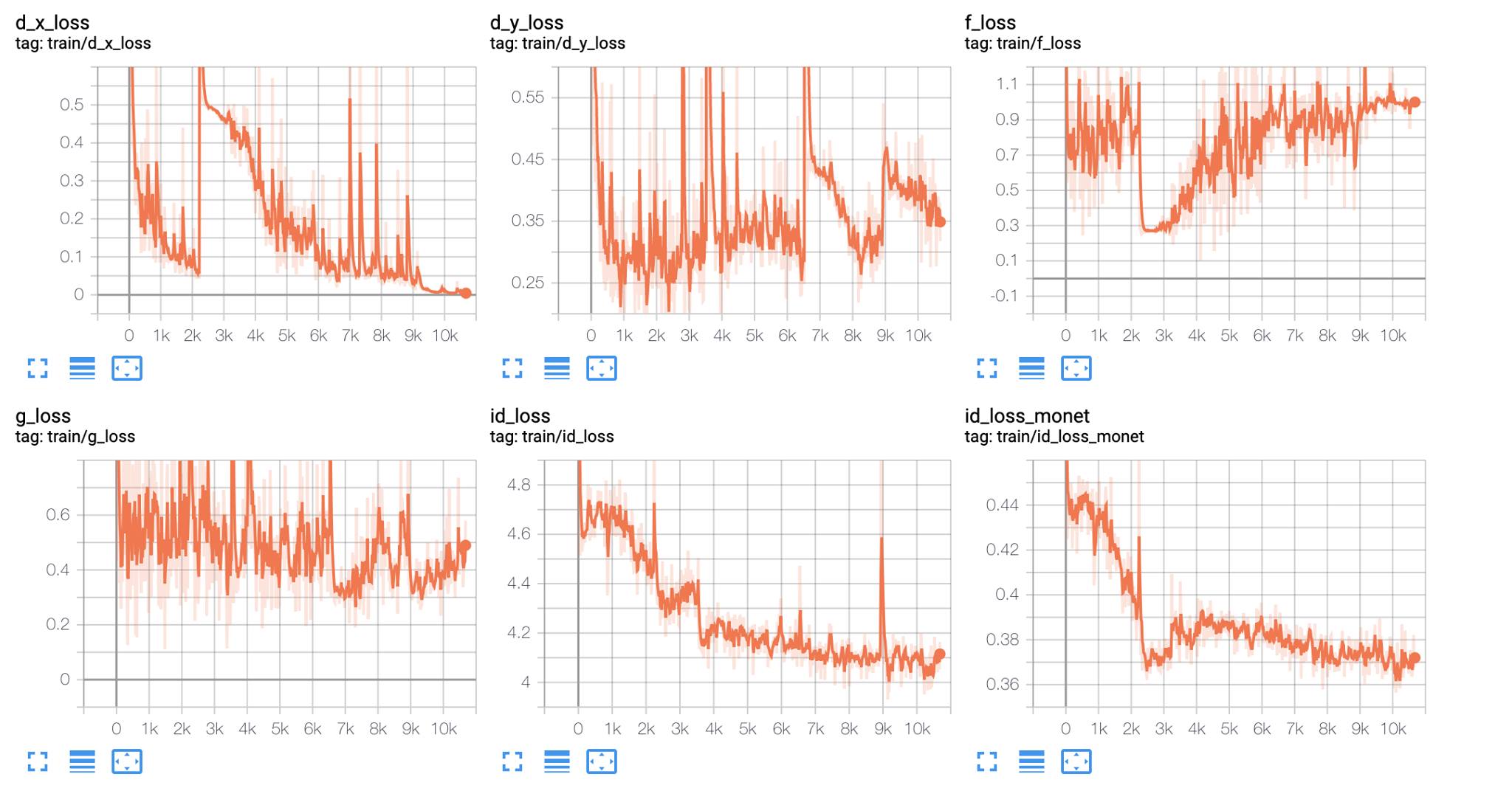 The loss graphs clearly show that the generator for monet -> photo (F) fails greatly and has high loss near 1.0
The loss graphs clearly show that the generator for monet -> photo (F) fails greatly and has high loss near 1.0
“The Master of Steganography”
Concluding that there was nothing wrong with the implementation after a thorough inspection of the code, I started to suspect that the generator might be sending invisible information among themselves in order to aid the reconstruction.
Neural nets tend to be lazy. By enforcing a cycle-consistency loss and assigning a large coefficient to the cycle-consistency loss term, we have let the generator models to focus on minimizing cycle-consistency loss term - by any means necessary. The two generators took the ‘shortcut’ by communicating with each other through high-frequency invisible codes that provide enough information to perfectly repaint the original image.
A paper by Chu et al. 2017 presented at NIPS 2017 Workshop “Machine Deception” clearly shows how these information are hidden by revealing the imperceptible information using adaptive histogram equalization.
 Image from “CycleGAN, a Master of Steganography”
Image from “CycleGAN, a Master of Steganography”
Hampering the hidden message by adding noise
The fix for this CycleGAN problem was rather simple; in order to prevent the invisible encoding, a weak random Gaussian noise was overlayed onto the generated images from one generator just before entering the other generator to reconstruct the original images. The generators could not fool us anymore by encoding secret information and had no choice but to generate authentic images as we have wished.
### G and F are generator models
# monet -> photo
gen_photo = G(monet_real)
# monet -> photo -> monet
gaussian_noise = 0.1 * random_normal(gen_photo.size())
monet_reconstructed = F(gen_photo + gaussian_noise)
cycle_fg = l1_loss(monet_real, monet_reconstructed)
 random noise added to generated image
random noise added to generated image
 nicely transformed styles after adding noise during cycle-consistency loss calculation
nicely transformed styles after adding noise during cycle-consistency loss calculation
Conclusion: Don’t get fooled by neural nets
The communication between two generators reminded me of the story about Facebook chatbots that have been shut down when they started communicating using seemingly nonsensical sequence of words. The story became famous due to numerous reports of suspicions about them having “invented a new language in order to elude their human masters”.

The case of CycleGANs show that small leak in the design for loss function might provide the means for neural nets to exploit and elude us. If the Facebook chatbots did invent a new language, it might be because inventing a new language was the proper, efficient way to optimize whatever training loss they were trained on. It is a somewhat common phenomenon that neural nets seem to be training properly looking by the metrics such as accuracy and training error, but does not actually behave as we want them to. As Andrej Karpathy points out in his post on neural net training recipe, “neural nets fails silently” and the errors are logical. However, in situations when training losses actually drop, neural nets might not be failing, but rather succeeding enormously just on whatever they are told to do. The faults are on humans that told them what to. For example, an autoregressive model simply learns the identity function due to the “off-by-one bug”, a human mistake, because that is the easiest way to achieve the goal.
When your model does not behave as you have expected but the numbers tell otherwise, look for the symptoms of neural nets “fooling” you, and think about what part of the design might be amended. It could be adding a noise, adding other types of regularizer, manipulating input data, or even changing the loss function completely. Be smart and don’t let the neural nets fool you!